LVM Snapshot Process
Reference: http://www.clevernetsystems.com/tag/cow/
This article explains how LVM snapshots work and what the advantage of read/write snapshots is.
We will go through a simple example to illustrate our explanation.
First, create a dummy device that we will initialize as a PV:
We now have a 1GB LVM2 Physical Volume.
We now have a Volume Group vg0 and a 400MB Logical Volume lv0. Let’s see what our device mapper looks like
We have a single device vg0-lv0, as expected.
Let’s take a snapshot of our Logical Volume:
We’ve created a 30 extents (120MB) snapshot of lv0 called snap1.
Let’s take a look at our device mapper:
This is interesting. We’d expect to see two devices. Instead, we have four. Let’s draw the dependencies:
A new device named vg0-snap1-cow is the device of size 30 extents (120MB) that will hold the contents of the snapshot.
A new device named vg0-snap1 is the device that the user will interact with.
Reading from the original volume
The user reads from vg0-lv0. The request is forwarded and the user retrieves data from vg0-lv0-real.
Writing to the original volume
The user writes to vg0-lv0. The original data is first copied from vg0-lv0-real to vg0-snap1-cow (This is why it’s called COW, Copy On Write). Then the new data is written to vg0-lv0-real. If the user writes again to vg0-lv0, modifying data that has already been copied to vg0-snap1-cow, the data from vg0-lv0-real is simply overwritten. The data on vg0-snap1-cow remains the data that was valid at the time of the creation of the snapshot.
Reading from the snapshot
When the user reads data from vg0-snap1, a lookup is done on vg0-snap1-cow to see if that particular piece of data has been copied from vg0-lv0-real to vg0-snap1-cow. If that is the case, the value from vg0-snap1-cow is returned. Otherwise, the data from vg0-lv0-real is returned. The user effectively sees the data that was valid at the time of creation of the snapshot.
A few important things to note:
With LVM2, as opposed to LVM1, the snapshot is read-write[In LVM1, the snapshot is read-only].
When the user writes to vg0-snap1, the data on vg0-snap1-cow is modified. In reality, what happens is that the a lookup is done to see if the corresponding data on vg0-lv0-real has already been copied to vg0-snap1-cow. If not, a copy is done from vg0-lv0-real to vg0-snap1-cow and then overwritten with the data the user is trying to write to vg0-snap1. This is because the granularity of the data copy process from vg0-lv0-real to vg0-snap1-cow might be bigger than the data the user is trying to modify. Let’s imagine that data is being copied from vg0-lv0-real to vg0-snap1-cow in chunks of 8KB and the user wants to modify 1KB of data. The whole chunk is copied over to the snapshot first. Then the 1KB are modified.
A second write to the same data will result in simply overwriting data in vg0-snap1-cow.
Removing an LVM snapshot
The following command will remove the snapshot:
The following command will merge the snapshot:
This article explains how LVM snapshots work and what the advantage of read/write snapshots is.
We will go through a simple example to illustrate our explanation.
First, create a dummy device that we will initialize as a PV:
# dd if=/dev/zero of=dummydevice bs=8192 count=131072
# losetup /dev/loop0 dummydevice
# pvcreate /dev/loop0
# pvs
PV VG Fmt Attr PSize PFree
/dev/loop0 lvm2 a-- 1.00g 1.00g
/dev/loop0 lvm2 a-- 1.00g 1.00g
# vgcreate vg0
# vgs
VG #PV #LV #SN Attr VSize VFree
vg0 1 0 0 wz--n- 1020.00m 1020.00m
vg0 1 0 0 wz--n- 1020.00m 1020.00m
# lvcreate -n lv0 -l 100 vg0
# lvs
LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert
lv0 vg0 -wi-a---- 400.00m
lv0 vg0 -wi-a---- 400.00m
# dmsetup table
vg0-lv0: 0 819200 linear 7:0 2048
Let’s take a snapshot of our Logical Volume:
# lvcreate -s -n snap1 -l 30 /dev/vg0/lv0
# lvs
LV VG Attr LSize Pool Origin Data% Move Log Copy% Convert
lv0 vg0 owi-a-s-- 400.00m
snap1 vg0 swi-a-s-- 120.00m lv0 0.00
lv0 vg0 owi-a-s-- 400.00m
snap1 vg0 swi-a-s-- 120.00m lv0 0.00
Let’s take a look at our device mapper:
# dmsetup table
vg0-lv0-real: 0 819200 linear 7:0 2048
vg0-snap1-cow: 0 245760 linear 7:0 821248
vg0-lv0: 0 819200 snapshot-origin 252:2
vg0-snap1: 0 819200 snapshot 252:2 252:3 P 8
vg0-snap1-cow: 0 245760 linear 7:0 821248
vg0-lv0: 0 819200 snapshot-origin 252:2
vg0-snap1: 0 819200 snapshot 252:2 252:3 P 8
LVM snapshots explained
We can see that LVM renamed our vg0-lv0 device as vg0-lv0-real and
created a new vg0-lv0 device. The user has now transparently switched to
using vg0-lv0.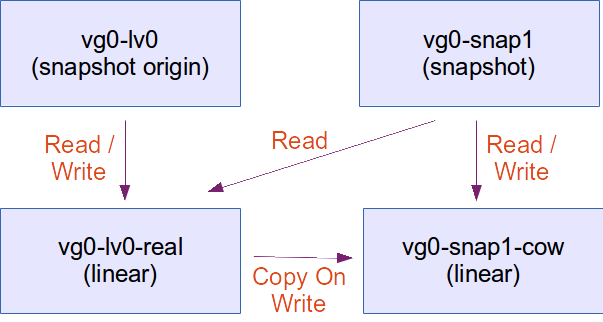
A new device named vg0-snap1-cow is the device of size 30 extents (120MB) that will hold the contents of the snapshot.
A new device named vg0-snap1 is the device that the user will interact with.
Reading from the original volume
The user reads from vg0-lv0. The request is forwarded and the user retrieves data from vg0-lv0-real.
Writing to the original volume
The user writes to vg0-lv0. The original data is first copied from vg0-lv0-real to vg0-snap1-cow (This is why it’s called COW, Copy On Write). Then the new data is written to vg0-lv0-real. If the user writes again to vg0-lv0, modifying data that has already been copied to vg0-snap1-cow, the data from vg0-lv0-real is simply overwritten. The data on vg0-snap1-cow remains the data that was valid at the time of the creation of the snapshot.
Reading from the snapshot
When the user reads data from vg0-snap1, a lookup is done on vg0-snap1-cow to see if that particular piece of data has been copied from vg0-lv0-real to vg0-snap1-cow. If that is the case, the value from vg0-snap1-cow is returned. Otherwise, the data from vg0-lv0-real is returned. The user effectively sees the data that was valid at the time of creation of the snapshot.
A few important things to note:
- The snapshot is empty at creation, whatever size it is. This means that the creation of a snapshot is immediate and invisible to the user.
- The snapshot will hold a copy of the original data, as the original data is modified. This means that the snapshot will grow over time. Therefore, it is not necessary to make a snapshot as big as the original volume. The snapshot should be big enough to hold the amount of data that is expected to be modified over the time of existence of the snapshot. Creating a snapshot bigger than the original volume is useless and creating a snapshot as big as the original volume will ensure that all data on the original volume can be copied over to the snapshot.
- If a snapshot is not big enough to hold all the modified data of the original volume, the snapshot is removed and suddenly disappears from the system, with all the consequences of removing a mounted device from a live system.
- A volume that has one or more snapshots will provide much less I/O performance. Remove the snapshot as soon as you’re done with it.
With LVM2, as opposed to LVM1, the snapshot is read-write[In LVM1, the snapshot is read-only].
When the user writes to vg0-snap1, the data on vg0-snap1-cow is modified. In reality, what happens is that the a lookup is done to see if the corresponding data on vg0-lv0-real has already been copied to vg0-snap1-cow. If not, a copy is done from vg0-lv0-real to vg0-snap1-cow and then overwritten with the data the user is trying to write to vg0-snap1. This is because the granularity of the data copy process from vg0-lv0-real to vg0-snap1-cow might be bigger than the data the user is trying to modify. Let’s imagine that data is being copied from vg0-lv0-real to vg0-snap1-cow in chunks of 8KB and the user wants to modify 1KB of data. The whole chunk is copied over to the snapshot first. Then the 1KB are modified.
A second write to the same data will result in simply overwriting data in vg0-snap1-cow.
Removing an LVM snapshot
The following command will remove the snapshot:
# lvremove vg0/snap1
- This operation is very fast because LVM will simply destroy vg0-snap1-cow, vg0-lv0 and vg0-snap1, and rename vg0-lv0-real to vg0-lv0.
- All data that has eventually been written to the snapshot (through vg0-snap1) is LOST.
The following command will merge the snapshot:
# lvconvert --merge vg0/snap1
Merging of volume snap1 started.
lv0: Merged: 100.0%
Merge of snapshot into logical volume lv0 has finished.
Logical volume "snap1" successfully removed
lv0: Merged: 100.0%
Merge of snapshot into logical volume lv0 has finished.
Logical volume "snap1" successfully removed
- The merge will start immediately if the filesystems in the original volume and in the snapshot are unmounted (i.e. if the volumes are not in use), otherwise the merge will start as soon as both filesystems are unmounted and one of the volumes is activated. This means that if a merge of the root filesystem is planned, it will happen after a reboot, as soon as the original volume is activated.
- This operation can take time, because data needs to be copied from the snapshot to the original volume.
- As soon as the merge begins, any read-write operation to the original volume is transparently redirected to the snapshot that is in the process of being merged. Therefore, the operation is transparent to the user who thinks he’s using the merged volume. This means that as soon as the merge begins, users interact with a volume that contains the data at the time of the creation of the snapshot (+ data that has eventually been written to the snapshot since then).
Comments
Post a Comment